
The Accuracy Killer: Weeding out False Positives
Sep 09, 2022
By Tracy Adams, Vice President of Engineering
Introduction
Training a visual machine learning model first involves labeling a set of images. The labels indicate what is present in an image, and in some cases, its bounding box or polygon. These labeled images are used to train an AI model to find the best set of weights that can accurately predict the presence of that object in a new image.
Generally, the first pass of this process is relatively smooth and the model soon generates some results. However, when deployed to the wild, subtle cases often appear. In reality, a first pass generally means that you are about half-way to a real-world practical solution.
False and True Positives
The FoxyAI Boarded Windows and Doors model detects and labels instances when windows and doors are covered with plywood or plexiglass.
The first pass of the FoxyAI Boarded Windows and Doors used typical images such as those on the right. The model did quite well on the training set, with precision and accuracy both well over 90%.

This initial version of FoxyAI Boarded Windows and Doors was deployed and did quite well identifying true positives on images never seen before.
However, we saw a number of very obvious and recurring false positives from commonly seen patterns such as staircases and wooden siding.
Perhaps surprisingly, the accuracy in detecting opaque coverings like plexiglass was much higher than the wood coverings. Although opaque coverings may be harder for a human to detect, there are fewer instances of similar patterns to plexiglass that trigger false positives from the model.
Context Matters

The collection and labeling of training images should also consider the specific usage or use-case scenario. An appraiser determining the quality and condition of a home has much different goals than a property preservation company hired to oversee the care and maintenance of a vacant property. A specific version of a model may also be developed for a specific geography. Building AI models for these different cases again depends on the data set.
As a very simple example, the images below represent house numbers. A model that is naively trained may also incorrectly identify images, such as street signs, as house numbers as well.

The FoxyAI Continuous Improvement Process
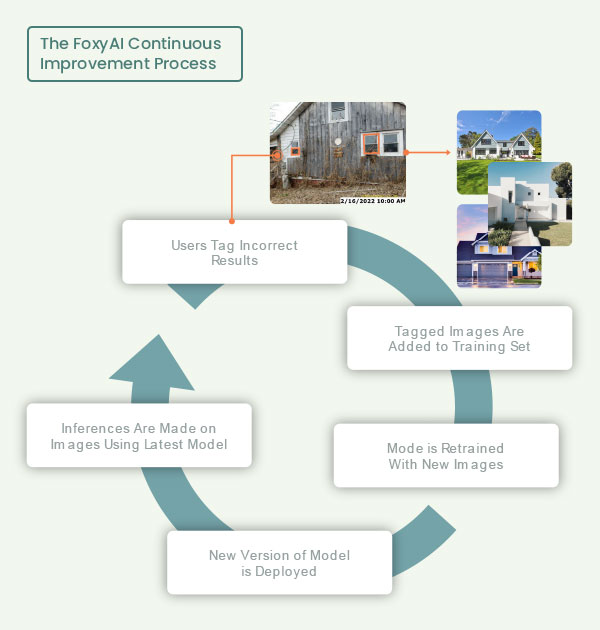
According to AI expert, Andrew Ng, “Deploying to production means you are halfway there”, training mass qualities of data is not useful if the right images are not present and properly labeled. The key is to create a continuous feedback loop where images are labeled, and incorrect results are fed back into the data set and used to retrain the model. We accomplish this continuous loop at FoxyAI by collecting user feedback via our API and feedback tags in our applications. Using this feedback, the set of training images are therefore refined and result in a more accurate model for our customers.
Continuous feedback loops in machine learning and AI is very much like real life. We learn from our mistakes.